java中jsoup解析爬虫获取的页面html数据,轻松实现一个爬虫
原创 2019-11-05 16:16:10.0 阅读(3528)次
最近在找工作,看看各大人才网上的工作岗位,搜索了一下自己住所附近的工作,搜索功能好像对地址搜索不是很友好,于是自己想爬一下各大人才网上的数据,以便自己好搜索,并不商用也不开放数据,话说最近反爬虫很严啊,不过想来自己只是爬取公开的数据,并且不会影响目标网站的正常运行,应该是没事的,这里也希望大家遵守爬虫协议。
jsoup是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据
以某人才网为例,把他的搜索地址中的搜索词和页码动态传入参数,用Jsoup解析dom就可以把想要搜索的岗位数据拿下来,然后自己放到数据直或搜索引擎中搜索,直接分享代码爬虫和jsopu部分代码:
import java.net.URLEncoder;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.goodjob.util.HttpUtil;
public class CrawlService {
public static String rcUrl = "https://www.xmrc.com.cn/net/info/Resultg.aspx?a=a&g=g&recordtype=1&searchtype=1&keyword=#_#&releasetime=365&sortby=updatetime&ascdesc=Desc&PageIndex=#-#&PageSize=100";
public void crawl(String keyword) {
crawlXmrc(keyword);
}
public void crawlXmrc(String keyword){
String keyurl = rcUrl.replaceFirst("#_#",URLEncoder.encode(keyword));//关键词
int page = 1;
int pageSize = 100;
int c = 1;
while (true) {
try {
Thread.sleep(1000l);
} catch (InterruptedException e) {
}
String pageUrl = keyurl.replaceFirst("#-#",page+"");//页码
String xmrcHtml = HttpUtil.httpsGet(pageUrl);
Document document = Jsoup.parse(xmrcHtml);//Jsoup解析html
Elements table = document.getElementsByClass("queryRecruitTable");//内容表格table
Elements tbody = table.select("tbody");
Elements trs = tbody.select("tr");
int size = trs.size();
for (int i = 0; i < size; i++) {
if (i!=0) {//第一行为标题
Element element = trs.get(i);
Elements tds = element.getElementsByTag("td");
Element jobNameTd = tds.get(1);//职位名称
Element companyNameTd = tds.get(2);//公司名称
Element addressTd = tds.get(3);//职位名称
Element monthlyPayTd = tds.get(4);//参考月薪
String jobName = jobNameTd.text();
String companyName = companyNameTd.text();
String address = addressTd.text();
String monthlyPay = monthlyPayTd.text();
System.out.println(c+"--"+jobName+"--"+monthlyPay);
c++;
}
}
if (size < pageSize+1) {//小于pagesize表示最后一页了
break;
}
page ++;
}
System.out.println("完成");
}
public static void main(String[] args) {
CrawlService crawlService = new CrawlService();
crawlService.crawl("java");
}
}DOM结构如下图:
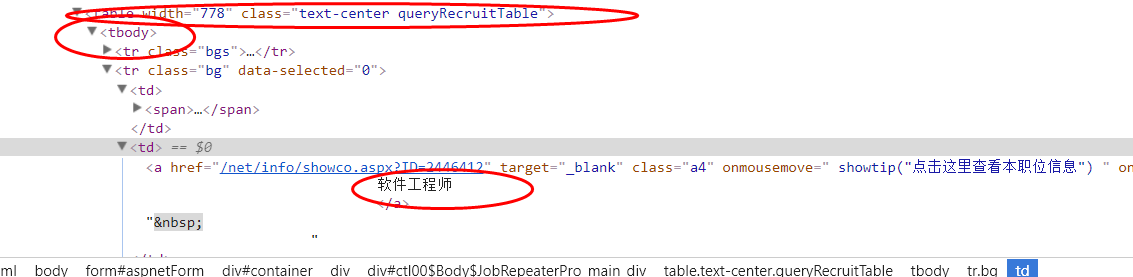
其中HttpUtil类在我的上一篇文章中有分享过,地址是http://www.classinstance.cn/detail/86.html
可以直接搬过去就能运行。
jsoup的maven pom文件:
<!-- jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.7.2</version>
</dependency>结果如下:
1--MES实施工程师 --6000-10000
2--中级Java开发工程师 --8000-12000
3--中级测试工程师 --7000-12000
4--高级Java开发工程师 --15000-20000
5--MES系统工程师 --8000-16000
6--.net工程师 --8000-12000
7--web前端 --7000-12000
....
另外爬虫经常要解析url中的参数,分享另一篇文章: